2020. 7. 5. 20:27ㆍData Science/04_Competition(Kaggle, Dacon)
M5 Forecasting 대회 종료
1) 대회 결과

: 상위 5% 이내 목표를 세웠지만 결과는 참담했다.
: 1,946위로 상위 16%에 해당하는 성적으로 마무리, 쉐이크업으로 인해 성적이 1,787등이나 내렸갔다.
: 아직 공부할게 많이 남아있다는 것에 위안 삼으며 이번 대회를 마무리 짓고자 한다.
2) LSTM 모델 코드
: 내가 초기 M5에 사용했었던 LSTM 모델 코드(pytorch)는 다음과 같다.
: Many to Many, Bidirectional 을 사용
: 초기 모델은 연산량이 많았던 모델이였기 때문에 학습 시간이 많이 소요됨
: 임베딩층을 쓰지 않고 hidden layers 개수를 줄여도 성능의 큰 차이는 없다.
class TimeDistributed(nn.Module):
def __init__(self, module, batch_first=False):
super(TimeDistributed, self).__init__()self.module = module
self.batch_first = batch_first
def forward(self, x):
if len(x.size()) <= 2:
return self.module(x)
x_reshape = x.contiguous().view(-1, x.size(-1))
y = self.module(x_reshape)
if self.batch_first:
y = y.contiguous().view(x.size(0), -1, y.size(-1)) # (samples, timesteps, output_size)
else:
y = y.view(-1, x.size(1), y.size(-1)) # (timesteps, samples, output_size)
return y
class LSTM(nn.Module):
def __init__(self, input_size=3053, hidden_layer_size=512, output_size=28,layers=2):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size, dropout=0.3, num_layers=layers, bidirectional=True, batch_first=True)
self.linear1 = TimeDistributed(nn.Linear(hidden_layer_size*2, 2048))
self.linear2 = TimeDistributed(nn.Linear(2048, 1024))
self.linear3 = TimeDistributed(nn.Linear(1024, 512))
self.linear4 = TimeDistributed(nn.Linear(512, 256))
self.linear5 = TimeDistributed(nn.Linear(256, 128))
self.linear6 = TimeDistributed(nn.Linear(128, 64))
self.linear7 = TimeDistributed(nn.Linear(64, 1))
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size),
torch.zeros(1,1,self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq)
# (batchsize, timestamp, hiddensize) 그대로 받기
linear1_out = self.linear1(lstm_out)
linear2_out = self.linear2(linear1_out)
linear3_out = self.linear3(linear2_out)
linear4_out = self.linear4(linear3_out)
linear5_out = self.linear5(linear4_out)
linear6_out = self.linear6(linear5_out)
predictions = self.linear7(linear6_out)
predictions = predictions.view(-1,28)
return predictions
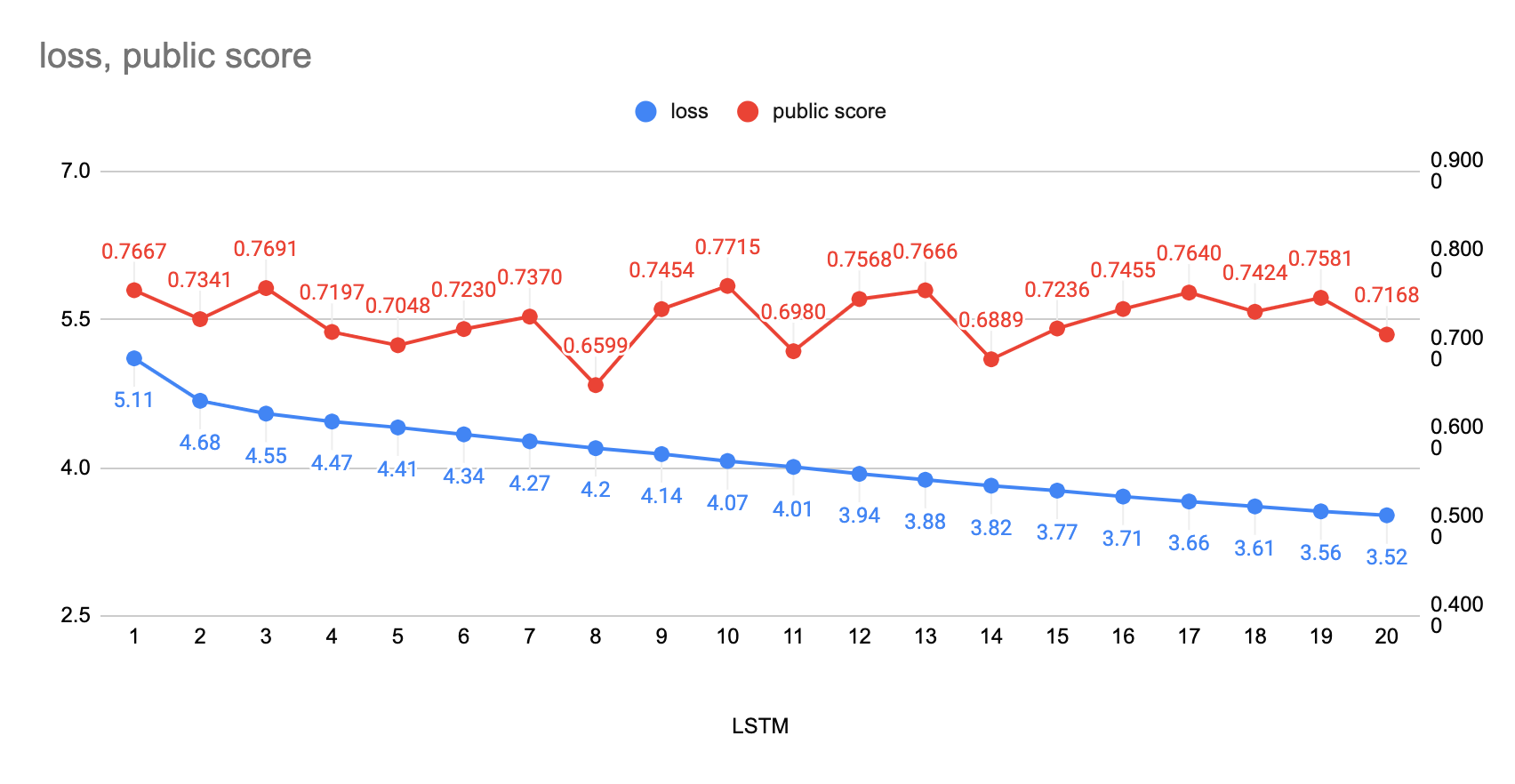
3) 내부 실험 결과
: LSTM 모델은 초기 학습에도 좋은 성능(Public score)을 나타냄
: 바닐라 모형 뿐만 아니라, 나중에 적용한 Seq2Seq 모델 또한 성능은 비슷했음
: Attention을 적용해봤지만 좋은 성능을 가져오지 못함
4) 아쉬운 점
: Transfomer Model을 구현해보지 못한 점
: 입력 데이터를 임베딩 혹은 2D Convnet에 태워보지 못한 점(나중에 꼭 실험해봐야함, FB DERT Model 참고하기)
: 메달 따지 못함점
'Data Science > 04_Competition(Kaggle, Dacon)' 카테고리의 다른 글
| 태양광 발전량 예측 AI 경진대회_Dacon(2/3부) (0) | 2021.02.26 |
|---|---|
| 태양광 발전량 예측 AI 경진대회_Dacon(1/3부) (0) | 2021.02.24 |
| M5 Forecasting_Kaggle (2/3부) (0) | 2020.06.24 |
| M5 Forecasting_Kaggle(1/3부) (0) | 2020.05.30 |
| Bengali_Kaggle(2/2부) (0) | 2020.05.04 |