2021. 2. 24. 22:40ㆍData Science/04_Competition(Kaggle, Dacon)
태양광 발전량 예측 AI 경진대회_Dacon(1/3부)

: 시계열 데이터 분석을 공부하면서 배운 내용을 실제로 활용해 보기 위해 해당 competition에 참가하게 됨
: 분석 주제는 지역의 기상 데이터와 과거 발전량 데이터를 활용하여, 시간대별 태양광 발전량을 예측(30분 단위)
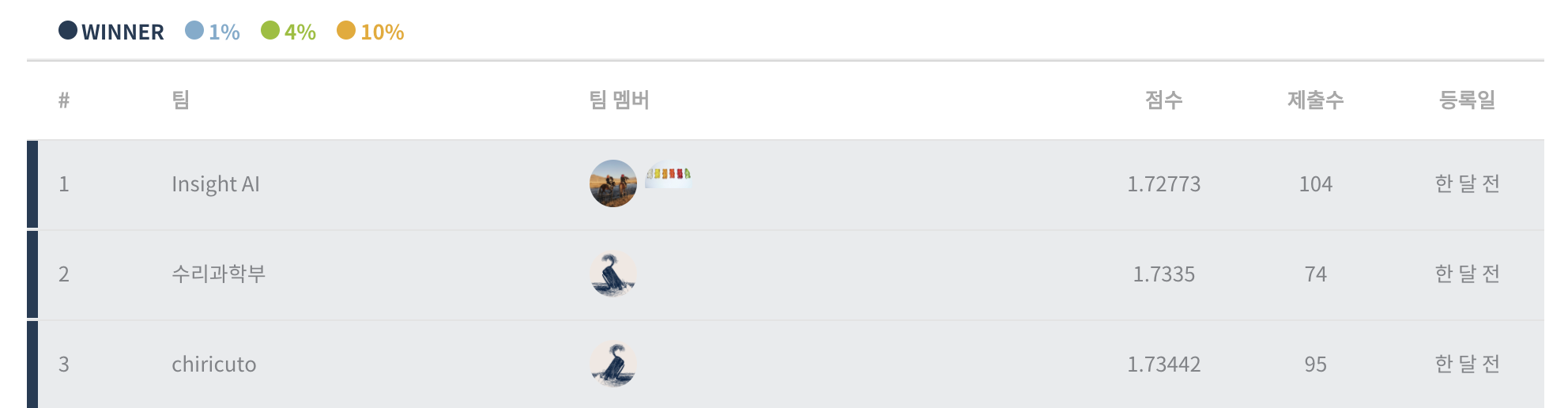
: 한 달이 넘는 기간동안 참가했으며 대회 종료까지 104회 제출하여 Public 1위, Private Top10 기록
: 해당 대회는 굉장히 큰 Shake Up이 발생해 최종적으로는 수상을 하지 못함
: 사실 local CV와 LB score가 굉장히 틀려 과적합을 의심했었지만 LB score의 미련을 버리지 못한 실수인지....
: 이번 대회에서는 모델링뿐만 아니라 FE(feature engineering)이 매우 중요했음
: 대회를 참가하면서 사용했던 모델과 분석 방법들을 해당 블로그를 통해 기록하고자 함
1. 데이터 설명
: 데이터 설명을 위해 1) 데이터 구조, 2) 변수 설명, 3) 평가 지표를 소개하고자 함
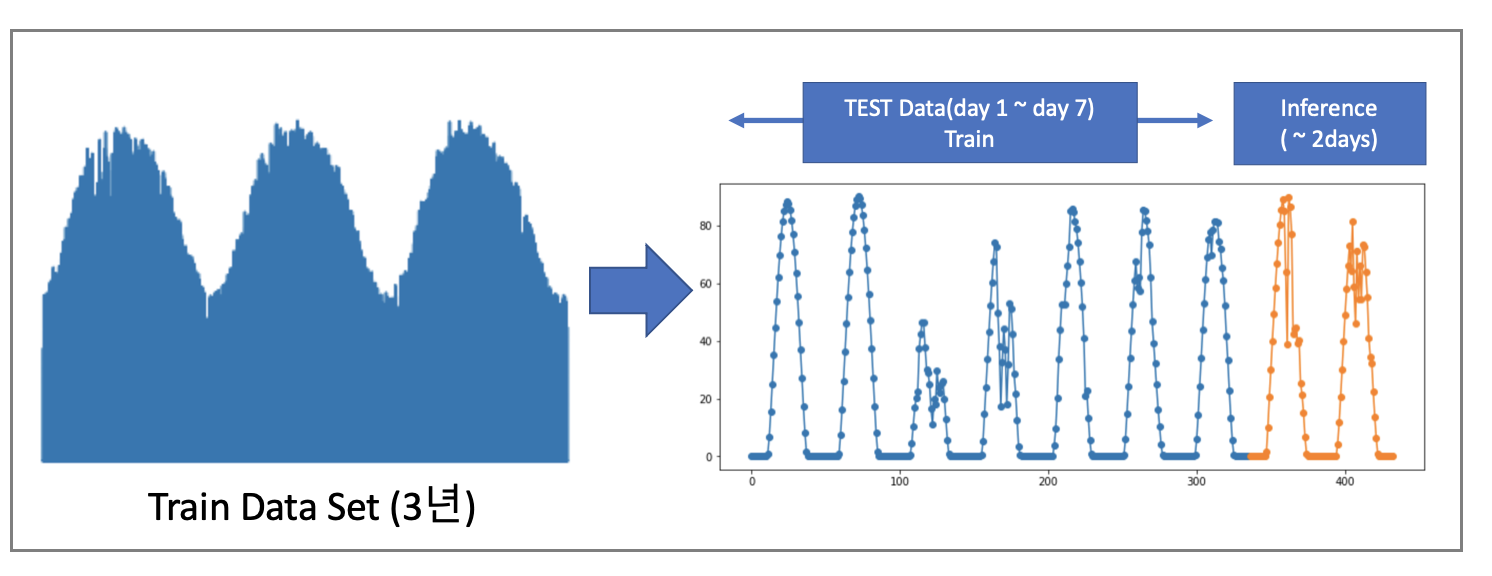
1-1) 데이터 구조
: 학습 데이터는 3년이며 예측해야 하는 테스트 데이터는 학습 데이터 이후 2년
: 모델은 7일(Day 0~ Day6) 동안의 데이터를 인풋 -> 향후 2일(Day7 ~ Day8) 동안의 30분 간격의 발전량(TARGET)을 예측
: 테스트 기간내 1일당 48개씩 총 96개 타임스텝에 대한 예측하는 문제
: 학습 기간 내 데이터를 활용하여 다양한 시도를 해볼 수 있는 구조로 대회가 진행됨
: 예측모델의 경우 Test Data의 7일간 데이터를 바탕으로 모델 학습에 사용해서는 안되며 오로지 학습 데이터만 사용 가능
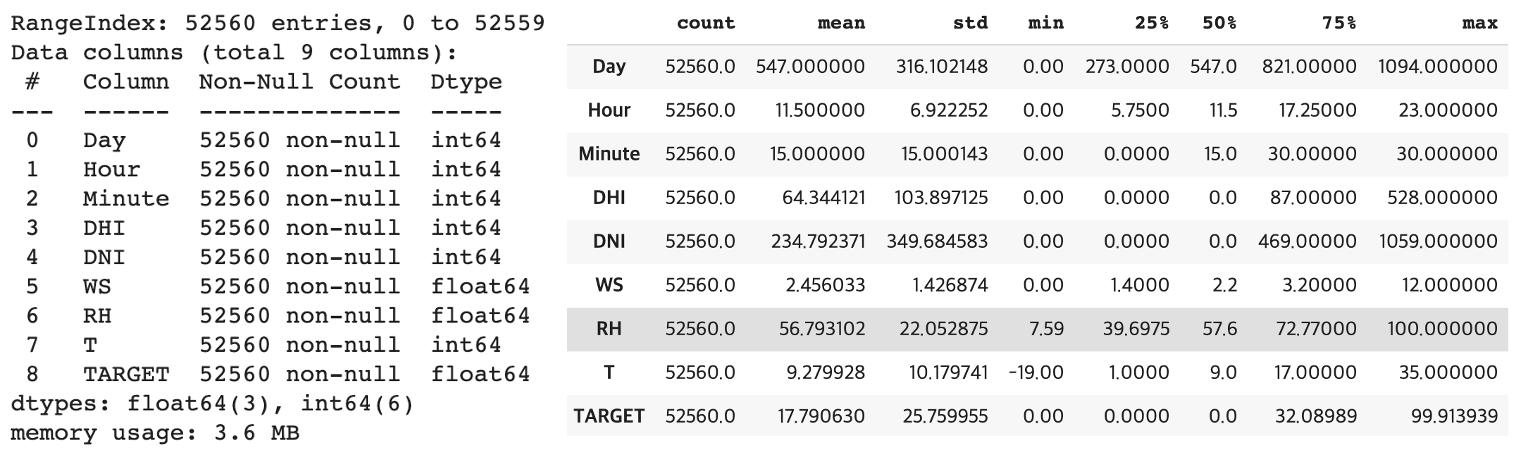
1-2) 변수 설명
: 전체 변수의 개수는 9개, 이중 8개의 독립 변수(Day, Hour.. 등)와 1개의 종속변수(TARGET)로 구성
: 시간과 관련된 변수 -> Day, Hour, Minute
: 일사량과 관련된 변수 -> DHI, DNI
: 기온과 관련된 변수 -> WS, RH, T
: 모든 변수들의 결측값은 존재하지 않으며 30분 단위로 측정되어 데이터가 축적됨
: 예측 분석에 사용할 때 Lag, Diff도 성능향상에 도움이 되었지만 시간과 기후, 일사량 관련된 파생변수들 중요
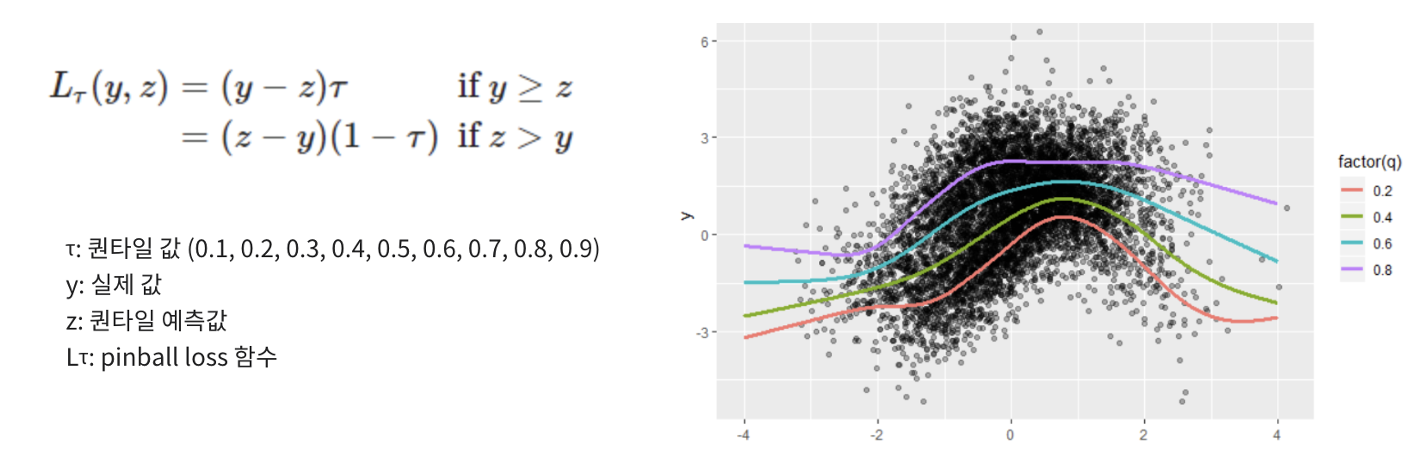
1-3) 평가 지표(Cost Function)
: 본 대회에서는 Pinball Loss를 사용하여 모델을 평가
: Pinball Loss를 해석해보면 높은 분위수에서는 실제값보다 크게, 낮은 분위수에서는 실제값보다 낮게 예측할수록 Loss를 줄일 수 있음
: Piball Loss을 살펴봤을때 가장 적합한 모델로 Quantile Reg(분위수 회귀)가 가장 먼저 떠오르게 됨
: 우리가 예측하는 문제들은 일반적으로 0.5 분위수를 기준으로 모델을 학습함
: 하지만 분위수 회귀는 결과 변수의 Q분위수를 기준으로 모델을 학습하여 추론하게 됨
: (다음편 예고) 다음 포스팅에서는 예측에 사용한 모델과 CV를 설명
'Data Science > 04_Competition(Kaggle, Dacon)' 카테고리의 다른 글
| 태양광 발전량 예측 AI 경진대회_Dacon(3/3부) (0) | 2021.03.06 |
|---|---|
| 태양광 발전량 예측 AI 경진대회_Dacon(2/3부) (0) | 2021.02.26 |
| M5 Forecasting_Kaggle(3/3부) (0) | 2020.07.05 |
| M5 Forecasting_Kaggle (2/3부) (0) | 2020.06.24 |
| M5 Forecasting_Kaggle(1/3부) (0) | 2020.05.30 |