2020. 10. 4. 12:45ㆍData Science/01_Machine Learning Study
Auto ML PyCaret
평소 Auto ML에 관심만 있었지 실제로 사용해보지 못했는데 연휴 동안 살펴보면서
Auto ML 패키지 중 접근성이 좋은 PyCaret을 소개해보고자 한다.
Home - PyCaret
Data Preparation in PyCaret Whether its imputing missing values, transforming categorical data, feature engineering or even hyperparameter tuning of models, PyCaret automates all of it. It orchestrates the entire pipeline no matter how complex it is.
pycaret.org
Auto ML이란
: 자동화 된 기계 학습은 기계 학습을 실제 문제에 적용하는 프로세스를 자동화하는 프로세스입니다. (출처: 위키백과)

설치 방법
해당 패키지 설치방법은 매우 간단하다.(홈페이지에 자세한 설명이 나와 있음)
Window, Mac 에서 모두 사용 가능하며 간단한 명령어 몇줄이면 금방 설치할 수 있다.
또한, Colab에서도 사용할 수 있어서 나는 실습을 Colab으로 진행하고자 한다.
# Colab 패키지 설치
!pip install pycaret
실습
위 코드를 Colab에서 실행하면 설치가 가능하다.
실습을 위한 데이터는 Kaggle 대표 Competition 중 하나인 'House Prices'를 사용함
www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
House Prices: Advanced Regression Techniques
Predict sales prices and practice feature engineering, RFs, and gradient boosting
www.kaggle.com
데이터 설명
: 데이터 크기는 다음과 같다.
Train shape = (1460, 81)
Tset shape = (1459,80)
X = 79개의 설명 변수(ID 제외)
Y = 1개 (SalePrice)

Auto ML 패키지 PyCaret을 경험해보기 위해 추가적인 전처리 작업을 진행하지 않고 바로 분석을 진행했다.
분석환경
1) 분석 환경 만들기(Setup)
추가적인 파라미터 설정은 홈페이지에 설명되어 있으니 참고해야 함
#함수 호출
from pycaret.regression import *
#환경 설정
reg = setup(train, target = 'SalePrice', train_size=0.8)
- 환결 설정 코드를 입력하면 2번의 입력창이 발생한다.
1) 데이터 형이 재대로 인식됐는지 확인 -> 문제 없으면 빈칸으로 Enter
2) Sample data 사용비율 확인(Train/Valid 비율) -> 전체 100% 사용시 빈칸으로 Enter

환경 구축이 완료되면 PyCaret은 다음과 같이 출력된다.
추가 확인해야 하는것들은 노란색 하이라이트가 되는데 결측치의 경우 해당 패키지에서 자동적으로 처리를 한다.
(Numeric - mean, Categorical - constant => default )
샘플 데이터 1,460개를 모두 다 사용했으며 이 중 Train 비율을 80%로 설정하여 데이터가 분할 되었다.

모델 비교
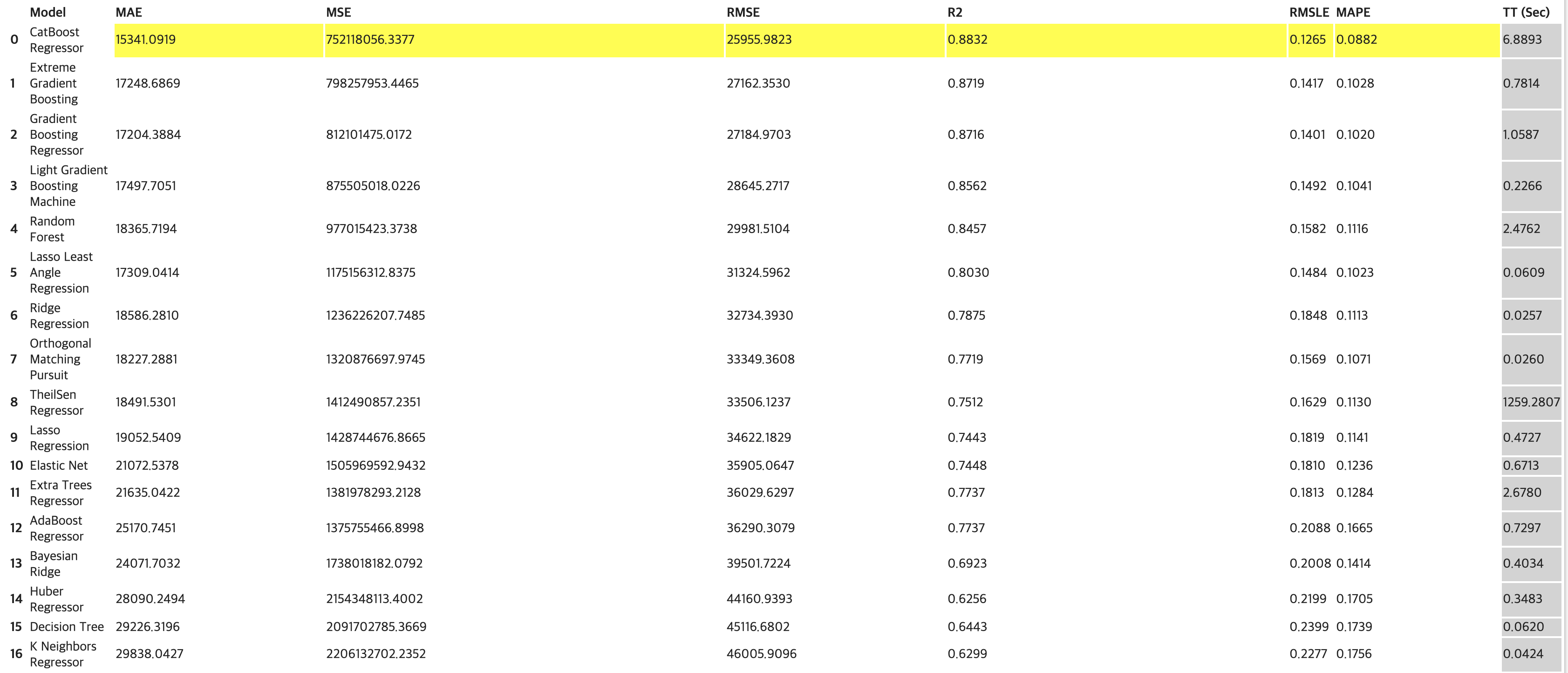
2) 모델 비교하기(Compare)
모델 비교의 경우 기본적으로 K-Fold CV로 값을 비교하게 된다.(K=10)
본 과업에서의 평가지표는 'RMSE' 이기 때문에 해당 지표를 기준으로 내림차순을 설정해 비교했다.
# 모델 비교하기
best = compare_models(sort = 'RMSE')
회귀 모델 22개의 성능 비교 Matrix를 출력해준다.
과업의 평가지표인 'RMSE'를 기준으로 내림차순 했으며 이 중 본인이 원하는 모델을 선택하여 다음 학습을 진행하면 된다.
모델 생성
3) 모델 생성(Create)
위 2) 모델 비교 결과를 기준으로 상위 3개의 모델만 생성해 활용해보기로 했다.
이미 성능 평가 비교를 했기때문에 CV = False
# 모델 생성하기
cat = create_model('catboost', cross_validation = False)
xgb = create_model('xgboost', cross_validation = False)
gbr = create_model('gbr', cross_validation = False)
하이퍼라미터 튜닝
4) 모델 하이퍼파라미터 튜닝(Tune)
모델 튜닝에는 기본적으로 K-Fold CV를 바탕으로 진행되며 최적화는 과업에 맞게 'RMSE"를 선택해 진행했다.
튜닝 방법은 일반적으로 Random Grid를 iter(default=10)만큰 최적화 시킨다.
해당 방법 외 custom grid 파라미터를 추가하여 튜닝을 진행할 수 있다.
# 하이퍼파라미터 튜닝
tuned_cat = tune_model(cat, optimize = 'RMSE', n_iter = 10)
tuned_xgb = tune_model(xgb, optimize = 'RMSE', n_iter = 10)
tuned_gbr = tune_model(gbr, optimize = 'RMSE', n_iter = 10)
블렌딩
5) 모델 블렌딩(Blend)
튜닝이 끝난 모델 3개를 앙상블 하는 작업이다.
기본적으로 전체 데이터셋을 사용하며 10-fold, RMSE로 최적화를 시켰다.
# 모델 블렌딩(Blend)
blender_specific = blend_models(estimator_list = [tuned_cat,tuned_xgb,tuned_gbr], optimize = 'RMSE')
오히려 일반 단일 모델에 비해 성능이 낮게 나왔다.
아마 튜닝 하는 과정에서 랜덤 서치다보니 성능이 매우 낮게 튜닝된듯 보인다.
하지만 앙상블 작업을 진행했기 때문에 단일 모델에 비해 일반화 성능은 아마 더 좋을것이다.

시각화
6) 모델 시각화(plot)
# 모델 시각화(plot)_plot = 'residuals'
plot_model(blender_specific)
- Train/Test 유사 분포
- Test set에 비해 Train set 설명력이 매우 높은것으로 보아 과적합을 의심
- Train/Test 모두 아웃라이어 제거가 필요해 보임

# 모델 시각화(plot)_plot = 'error'
plot_model(blender_specific, plot='error')

# 모델 시각화(plot)_plot = 'learning'
plot_model(blender_specific, plot='learning')
- Training Instances 1000회까지 CV가 상승추세를 보아 어느정도 깊게 학습해도 일반화에 큰 무리가 없어 보임
- score = 'AUC' defalut로 지정되어 있음

학습 및 예측
7) 마지막 학습 및 예측(Finalize, Predict)
# 마지막 학습(Finalize)
final_model = finalize_model(blender_specific)
# 예측(Predict)
pred = predict_model(final_model, data = test)
Auto ML 패키지 중 Pycaret 을 가지고 캐글 문제에 도전해봤다.
Pycaret의 순위는 전체 4,646명 중 3,610위를 기록했다.
기본 설정으로만 모델링을 했기때문에, 세부 튜닝을 한다면 어느정도 좋은 결과를 가져올 수 있을 것 이다.

Pycaret 을 활용해서 문제를 풀어본 결과
1) 시간대비 빠르게 Champion Model 을 찾을 수 있다.
2) 다양한 실험이 가능하다.
3) 손쉽게 하이퍼 파라미터 튜닝이 가능하다.
4) blend, stack, plot 등 손이 많이 가는 작업을 한줄로 해결 가능해서 편리하다.
시간 대비 효율이 좋지만, 실무에 있어서 아직까지는 탐사용으로만 사용하는게 좋을것 같다.
'Data Science > 01_Machine Learning Study' 카테고리의 다른 글
| 파이토치 허브(PYTORCH HUB) (0) | 2022.07.13 |
|---|---|
| 분위수 회귀(Quantile Regression) with Python (2) | 2021.07.22 |
| 단순회귀모형_단순회귀분석(2/2부) (0) | 2021.03.14 |
| 단순회귀모형_단순회귀분석(1/2부) (0) | 2021.03.10 |
| Prophet을 활용한 Kaggle 문제 풀어보기 (0) | 2021.02.25 |