2022. 1. 29. 16:43ㆍData Science/05_Research paper

Tabular data에서 우수한 성능을 냈던 Tree based ensemble Model의 특징을 딥러닝에 적용하기 위한 TabNet: Attentive Interpretable Tabular Learning 논문을 소개하고자 합니다.
CONCEPT
현실 세계 데이터는 딥러닝에서 가장 일반적으로 사용되는 정형 데이터임에도 불구하고 1) 빠르게 개발할 수 있고, 2) 성능이 우수하며, 3) 높은 해석력을 가지고 있는 트리 기반 앙상블 모델들로 문제를 해결하고 있습니다. 논문 저자는 트리 기반 앙상블 모델들이 딥러닝에 비해 정형 데이터에서 학습에 보다 논리적이고 합리적인 접근 방법이라고 소개합니다. 왜냐하면 일반적으로 관측되는 정형 데이터는 대략적인 초평면(hyperplane) 경계를 지니고 있는 매니폴드(manifolds)를 가지고 있으며 이 공간에서는 트리 기반 앙상블 모델의 결정 방식이 이해(representation)하는데 더 강점을 지니고 있기 때문입니다.
도메인 별 데이터 패턴(spatial locality, sequential dependency)을 보다 잘 학습시킬 수 있는 방법론(Convolution, Recurrent)을 사용해 접근하는 딥러닝은 해당 데이터에서 다른 머신러닝 방법들에 비해 우수한 성능을 보입니다. 이미지와 언어 같은 비정형 데이터들은 정형 데이터들에 비해 상대적으로 같은 원천에서 발생된 데이터이기 때문에 대략적인 초평면 경계가 뚜렷하지 않습니다.
CNN, MLP와 같은 딥러닝 모델은 적절한 귀납적 편향(inductive bias)의 부족으로 지나치게 Overparametrized 되어 정형 데이터 내 매니폴드에서 일반화된 해결책을 찾는데 어려움을 발생시길 수 있습니다. 그럼에도 불구하고 이런 딥러닝 학습 방법론을 정형 데이터 학습에 사용하고자 하는 이유는 다음과 같습니다.
이미지나 다른 종류에 데이터와 정형데이터를 함께 학습(Multi-Modal)할 수 있으며 트리 기반 모델 성능의 핵심인 Feature Engineering과 같은 작업이 크게 필요하지 않습니다. 또한, 스트리밍 데이터 학습이 용이하고 종단간(end-to-end) 모델은 Domain adaptation, Generative modeling, Semi-supervised learning과 같은 가치있는 응용 모델과 같은 표현 학습(representation learning)이 가능합니다.
위와 같은 이유로 딥러닝의 장점이 있기 때문에 논문의 연구팀은 다음과 같은 특징을 지닌 TabNet 구조를 제안했습니다. TabNet은 원자료의 다른 전처리 없이 입력할 수 있고 경사하강법 최적화 방법을 통해 유연한 통합(flexible integration)이 가능한 종단간(end-to-end) 학습이 가능합니다. 또한, 순차적 집중(sequential attention)을 사용하여 각 의사 결정 별 원인이 되는 변수를 선택함으로써 더 나은 해석 능력과 학습이 가능하며 숨겨진 특징을 예측하기 위해 사전 비지도 학습을 사용하여 정형 데이터에 중요한 성능 향상을 보여줍니다.(Self-supervised learning)
STRUCTURE
TabNet을 이루고 있는 주요 구조를 설명합니다.
(1) Feature Transformer
Feature Transformer는 4개의 네트워크 묶음(FC -> BN -> GLU)으로 구성되어 있습니다. 이때 사용된 GLU(Gated Linear Unit)는 Language Modeling with Gated Convolutional Networks에서 처음 소개된 구조입니다. 기본 아이디어는 LSTM에서 사용된 개념과 유사하며 각 정보 별 정보의 양을 얼마나 흘려보낼지 결정하기 위해 비선형 함수를 사용합니다. 전체 구조에서 앞 2개의 네트워크 묶음은 모든 파라미터를 공유하며 글로벌 성향을 학습하고 뒤 2개의 네트워크 묶음은 독립적으로 결정해 각 로컬 성향을 학습합니다.

(2) Attentive Transformer
Attentive Transformer는 현재 의사결정 단계에서 각 변수들이 얼마나 영향을 미쳤는지 사전 정보량(Prior scales)으로 집계합니다. 사전 정보량(Prior scales)은 선택된 변수의 반영률 조정하는 요인이며 중요 변수를 선택하고 각 변수 별 계수값들의 일반화(Normalization)를 위해 Sparsemax를 사용합니다.

(3) ENCODER
Encoder의 경우 1)feature transformer, 2) attentive transformer, 3) feature masking으로 구성되어있습니다. 과정을 살펴보면 첫 의사 결정 단계에서 부족한 부분을 다음 의사 결정 단계에서 보완하는 방식으로 진행되며 해당 분석 방식은 트리 기반 부스팅 모델과 유사합니다. 이때 feature masking은 local 해석에 사용되며 전체 취합시 global 해석을 할 수 있습니다.

(4) DECODER
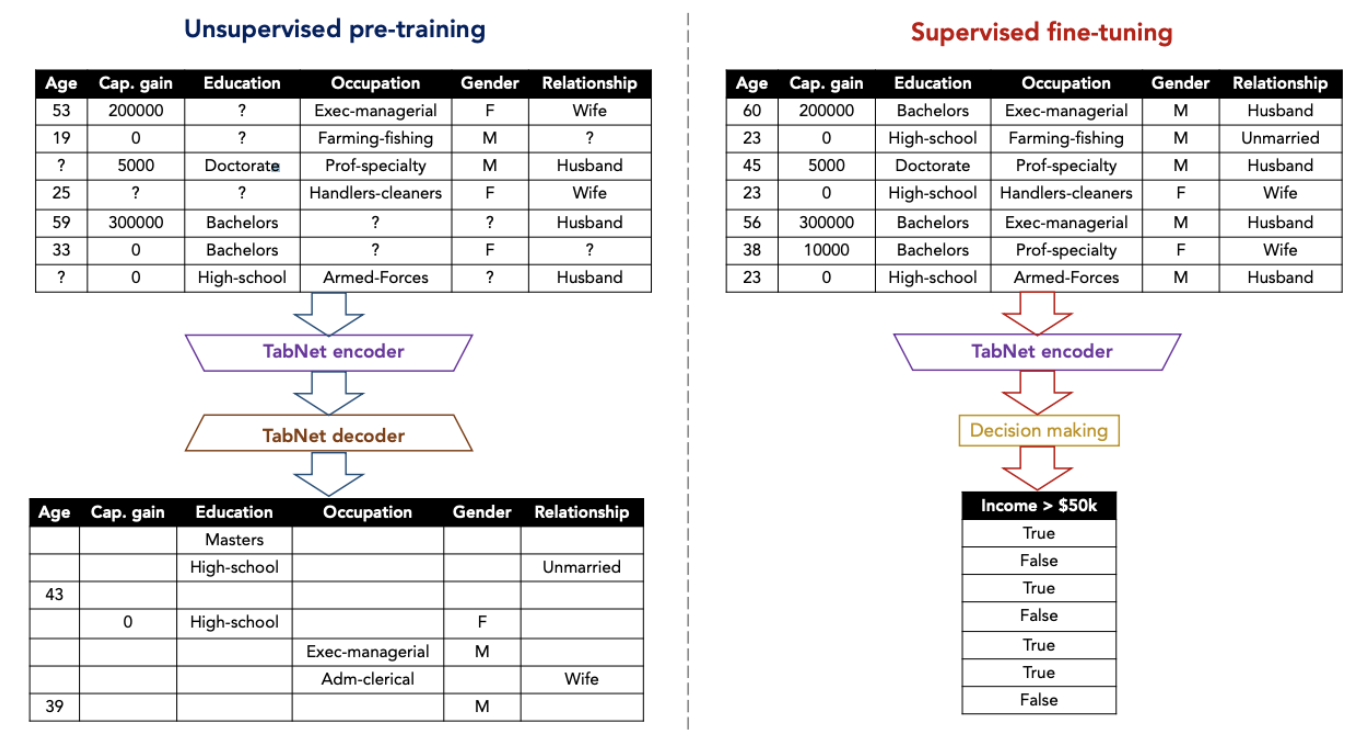
Decoder의 경우 각 단계별 feature transformer로 구성되었습니다. 일반 학습에서는 Decoder를 사용하지 않지만 Self-supervised 학습 진행시 인코더 다음 붙여지며 기존 결측값 보완 및 표현 학습을 진행합니다.

FEATURES
(1) Sparse Feature Selection(=Decision Blocks)
위 그림은 TabNet의 Sparse Feature Selection을 설명하기 위해 성인 인구 조사 데이터를 바탕으로 소득을 예측하는 과정입니다. Sparse Feature Selection은 가장 두드러진 특징을 가진 파라미터(capacity)들만 사용되기 때문에 해석력과 더 나은 학습이 가능합니다. 추론(Reasoning)을 위해 입력 변수들의 부분 집합 처리에 집중하는 여러개의 의사결정 블록(decision blocks)을 사용하며 그림에서는 income level을 예측하기 위해 2개의 의사결정 블록이 각각 전문직(professional occupation)여부와 투자액(investments)에 대해 관련된 변수가 선택된 것을 예시로 볼 수 있습니다.

(2) DT-like classification using conventional DNN blocks
의사결정나무와 같은 변수 선택 방법을 딥러닝에 적용하기 위해 TabNet에서는 입력 변수들 중 선택 변수 외 다른 변수들을 가리는 방법(multiplicative sparse masks)을 적용하고 선택 변수는 선형 결합 후 편향(bias)이 추가되어 비선형 함수(Relu)로 출력합니다. 편향(bias)은 결정 경계(boundares)를 표현하기 위해 더해졌으며 서로 상호독립적인 출력값(의견)을 결합하여 의사 결정을 진행하는 방식은 의사결정나무와 유사한 문제해결방법입니다. 각 변수 별 특징은 가중치 Ck에 의해서만 차이를 지니게 되고 이 값이 커질수록 결정 경계가 뚜렷해집니다.

(3) Self-supervised tabular learning
현실 세계 데이터로 구성된 정형 데이터에는 서로 상호 의존적인 변수들이 존재하기 때문에 직업에서 교육 수준을 추측하거나 관계를 통해 성별을 추측할 수 있습니다. TabNet에서는 자기지도학습(Self-supervised)을 위해 무작위로 가려진(masked) 변수값을 예측하는 encoder-decoder 구조의 비지도 학습을 수행하여 비지도 표현(Unsupervised representation)을 학습해 encoder 구조의 지도학습 모델 성능을 향상시킬 수 있습니다.
(4) Feature importance masks
Syn2 dataset을 살펴보면 M agg는 Global 설명력을 나타내며 이는 Test Sample 별 어떤 변수들이 상대적으로 중요했는지 나타내며 M1 ~ M4의 경우 각 의사결정 블록에서 샘플별 어떤 변수들이 가장 중요했는지 표현해줍니다. 우리는 이를 통해 모델을 보다 잘 해석할 수 있습니다.

Performance
위에서 기술된 특징들로 인해 TabNet은 다양한 도메인의 정형데이터에서 기존 트리 기반 앙상블 모델들에 비해 우수한 성능을 보여줍니다.

Lessons Learned
연구팀이 기존 정형 데이터에서 트리 기반 앙상블 모델들이 왜 성능이 좋았는지에 대해 분석하고 이 특징을 딥러닝에 적용해 문제를 해결해 나가는 방식이 매우 논리적이고 합리적이였습니다. 평소 정형 데이터를 다룰때 전처리 과정과 변수 선택하는 과정에 많은 시간과 어려움을 가지고 있었는데 TabNet을 활용하여 방법도 같이 고려해봐야겠습니다.
아래 Tabnet에 대한 Example을 코랩으로 구현해 사용한 파일이 있으니 참고하시길 바랍니다.
Reference
[Paper] TabNet: Attentive Interpretable Tabular Learning
[Code] Tensorflow - tabnet
[Code] Torch - tabnet
[Code] Example - tabnet
'Data Science > 05_Research paper' 카테고리의 다른 글
| LTSF-Linear(DLinear, NLinear) 논문 리뷰/구현(Are Transformers Effective for Time Series Forecasting?) (28) | 2023.01.01 |
|---|---|
| Generative Adversarial Nets_GAN_CODE (0) | 2021.03.02 |
| Generative Adversarial Nets_GAN_Overview (0) | 2021.03.02 |