2022. 5. 23. 16:53ㆍData Science/02_Time Series Analysis
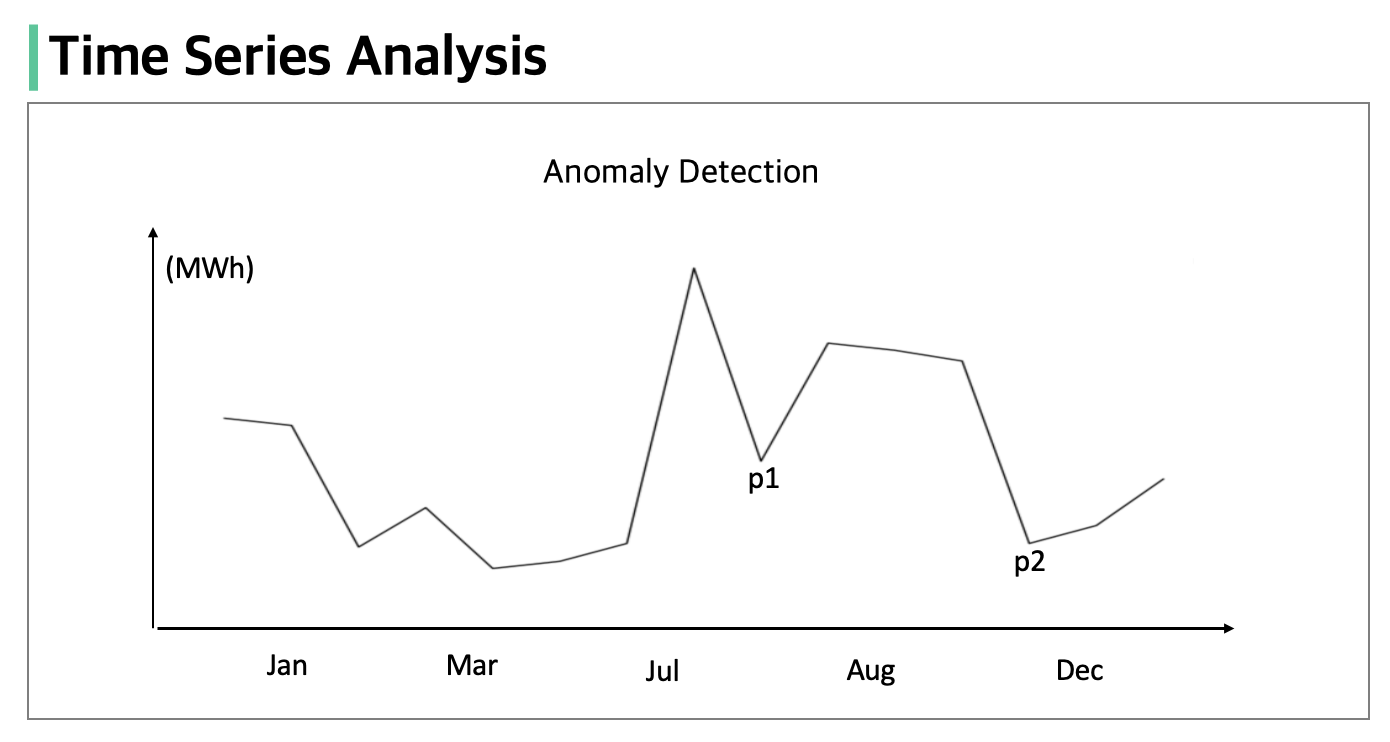
시계열 데이터 이상 탐지는 시간 흐름에 따른 평균과 분산을 고려하는 방법론을 주로 사용합니다. 예를 들어 설명하면, 위 그림과 같이 월별 전력사용량에서 anomaly가 의심되는 두 지점(p1, p2)을 살펴보면 여름에 높은 전력사용량이 의심되는 p1이 감소하는 계절의 p2보다 anomaly일 가능성이 높습니다. 그래서 시계열 데이터의 경우 context를 고려한 이상 탐지 모델을 설계해야 비용 절감과 좋은 성능의 모델을 만들 수 있습니다.
Anomaly
Anomaly란 일반적인 데이터와는 다른 메커니즘에 의해 발생된 데이터(1980, Hawkins) 혹은 확률 밀도가 낮은 빈도의 데이터(2006, Harmeling) 등 다양하지만 일반적이 않은 데이터라고 정의됩니다. 그리고 Anomaly는 주가 급듭 신호와 같이 긍정적인 표현으로 쓰이는 Novelty, 불량 신호와 같이 부정적인 표현으로 쓰이는 Abnormal, 일반 범위를 극단적으로 벗어나는 Outlier 등 다양한 용어로도 표현됩니다.
이렇듯 분야 및 문제마다 다르게 정의될 수 있기 때문에 Anomaly Detection은 특정한 방법론이 존재하지 않고 정의한 문제에 따라 활용 가능한 모든 방안들을 사용합니다.
Approaches
Anomaly Detection 문제를 정의하고 구체적으로 모델을 설계하기 위한 접근방법을 설명하겠습니다.(2009, Varun Chandola)
(1) Nature of Input Data
이상 탐지의 가장 중요한 요인은 입력 데이터의 특징입니다. 데이터의 특성이 범주형/연속형인지 하나의 속성(univariate)/다중 속성(multivariate)을 지닌 것인지 발생이 독립적(independent)/상호의존적(Relational)인지를 파악해야 합니다. 입력 데이터 특징에 따라 서로 다른 통계 모델 혹은 방법론을 적용해야 올바른 결과를 얻을 수 있습니다.
(2) Type of Anomaly
Anomaly의 종류는 크게 3가지로 나눌 수 있습니다.
(2-1) Point Anomalies
Point Anomalies는 일반적으로 가장 많이 접하고 쉬운 유형이며 대부분 연구의 초점이 됩니다. Point Anomalies는 기존 수집된 데이터의 정적인 정상 분포의 초점을 두고 이와 다른 유형을 파악합니다.(ex. card fraud detection)
(2-2) Contextual Anomalies
Contextual Anomalies는 주로 시계열(TimeSeries)과 공간(spatial) 데이터에서 연구되었습니다. Contextual Anomalies는 Contextual과 Behavioral 두개의 동적인 고유 특성을 지니고 있어 이를 바탕으로 다른 유형을 파악합니다.
(2-3) Collective Anomalies
Collective Anomalies는 연속형(Sequence)과 그래프(Graph) 데이터에서 연구되었습니다. Collective Anomalies는 데이터 집합이 전체 데이터 집합과 비교하여 다른 유형을 파악합니다.
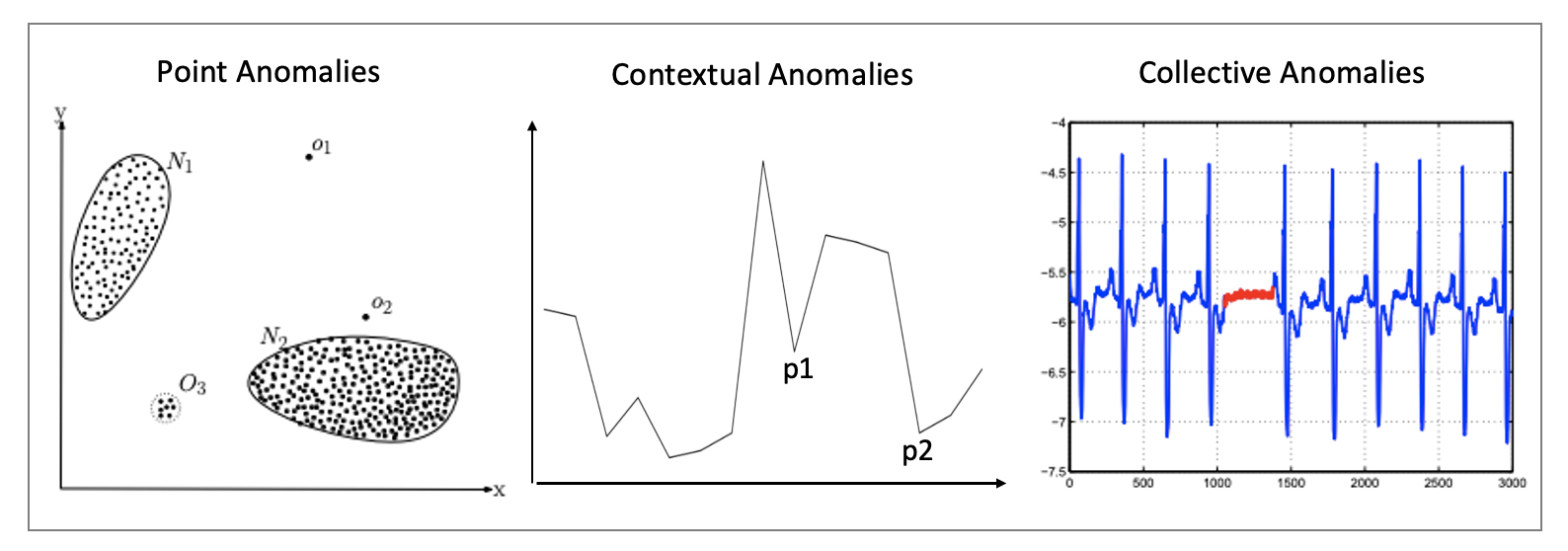
Point Anomalies는 전체 데이터내에서 발생할 수 있으며 Contextual Anomalies는 관련 있는 데이터 집단 내에서만 발생 가능합니다. 이와 대조적으로 Collective Anomalies는 전체 혹은 집단 내 데이터 context의 따라 발생할 수 있습니다. 그러므로 하나의 방법론만 사용해 Anomaly Detection을 진행하는 게 아니라 상황에 따라 복합적으로 활용할 수 있어야 합니다.
(3) Data Labels
정확한 Data Labels는 전문가가 직접 작업해야하는 일이기 때문에 큰 비용을 듭니다. 그리고 전문가를 통해서 얻은 정답이 있다 하더라도 비정상적인 것은 본질적으로 역동적이기 때문에 항상 새로운 유형이 발견될 수 있다는 것을 염두해둬야 합니다. 사용 가능한 Data Labels의 따라서 Anomaly Detection은 다음과 같은 방법들을 사용할 수 있습니다.
(3-1) Supervised Learning
정상과 비정상에 대한 Data Labels가 모두 존재한다면 사용하는 방법론입니다. 이 경우에는 일반적으로 정상 대 비정상에 대한 분류를 문제로 정의하고 모델링합니다. 비교적 간단하면서도 좋은 성능을 내기 때문에 BaseLine 모델로 활용합니다. 그러나 지도 학습 방법에는 크게 두 가지 문제가 주로 발견되는데 1) 데이터 불균형과 2) 새로운 비정상에 대한 탐지의 어려움입니다.
(3-2) Semi-Supervised Learning
정상에 대한 Data Labels가 존재한다면 주로 사용하는 방법론입니다. 비정상에 대한 데이터가 필요하지 않기때문에 지도 학습 방법론에 비해 더 광범위하게 적용 가능합니다.
(3-3) Unsupervised Learning
정상과 비정상에 대한 Data Labels가 모두 존재하지 않는다면 사용하는 방법론입니다. 이 방법은 Data Labels가 필요하지 않기때문에 지도/준지도 학습에 비해 더 광범위하게 적용 가능합니다. 비지도 학습 방법론은 데이터의 이상이 훨씬 빈번하다는 암묵적인 가정을 하고 모델링하기 때문에 더 많은 이상을 찾게 됩니다.
(4) Output of Anomaly Detection
Anomaly Detection에서 가장 중요한 기술은 결과에 대한 보고이며 크게 Score과 Lables 두가지 방법으로 제안됩니다. Score는 임계값을 사용하여 Anomaly를 판단하며 도메인별 정확한 탐지가 용이합니다. Labels는 도메인에 대한 이해가 부족한 경우 기술적인 결괏값을 활용하여 탐지가 가능합니다.
Anomaly Detection 문제를 정의가 끝났으면 그에 맞는 방법론을 사용하여 분석을 진행합니다.
Techniques
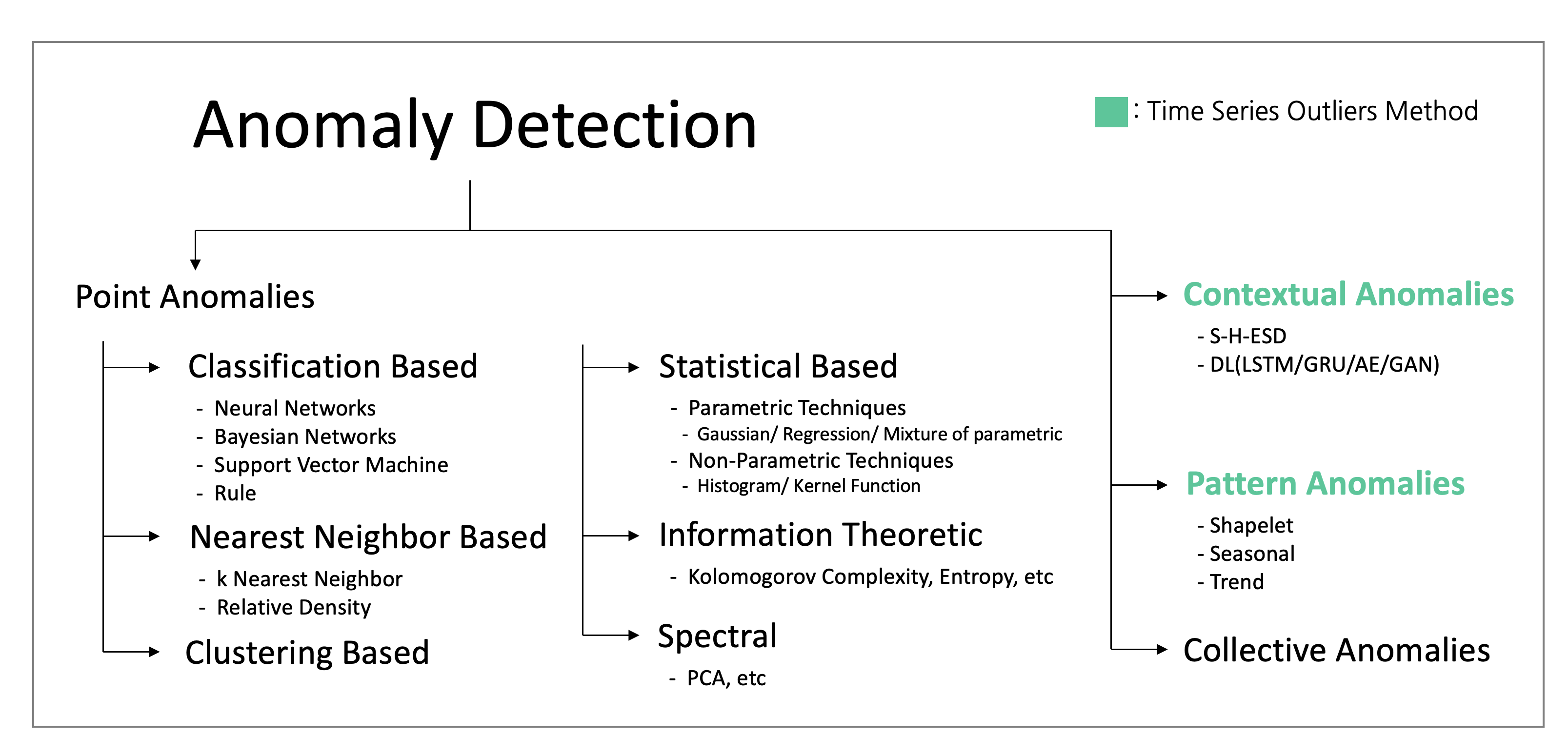
Anomaly 종류에 따라 중점적으로 활용되는 분석 방법이 달라집니다. 예를 들어 시계열 데이터의 경우 Contextual Anomalies, Pattern Anomalies로 분류 되기 때문에 과거부터 주로 사용되었던 S-H-ESD, DL, Shapelet 등 방법들로 먼저 접근하는 것을 추천드립니다. 그리고 Point Anomalies에서 사용
이번 포스팅에서는 시계열 데이터에서 Contextual Anomalies를 탐지하는 방법론을 예제를 통해 살펴보겠습니다.
(작성 예정...)
'Data Science > 02_Time Series Analysis' 카테고리의 다른 글
| 시계열 데이터 예측 모델링(Stacked Hybrids) (1) | 2022.03.26 |
|---|---|
| 시계열 데이터 전처리(Denoising Method) (7) | 2022.02.13 |
| 시계열 데이터 전처리(Encoding Time Step Features) (2) | 2022.01.31 |
| 다변량 선형 확률과정(VAR/Granger Causality/Cointegration) (1) | 2021.01.07 |
| 시계열 데이터 분석 싸이클 (0) | 2021.01.04 |