시계열 데이터 전처리1
2020. 12. 10. 15:36ㆍData Science/02_Time Series Analysis
반응형
시계열 데이터패턴
: 시계열 데이터 분석에 있어 파생변수를 만드는 것은 가장 중요하고 시간이 많이 걸리는 작업
: 변수 생성시 주의해야 할 2가지
- 미래의 실제 종속 변수 예측값이 어떤 독립/종속 변수의 FE에 의해 효과가 있을지 단정지을 수 없음
- 독립변수의 예측값을 FE를 통해 생성될 수 있지만 이는 종속변수 예측에 오류를 야기할 수 있음
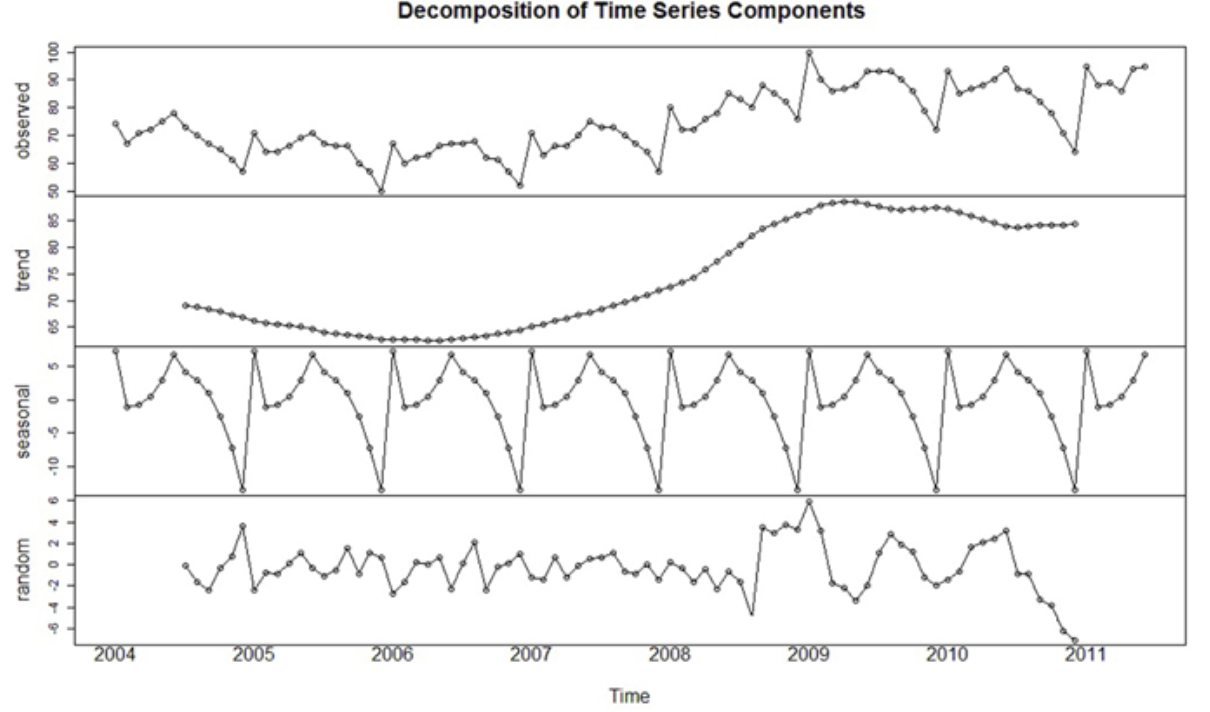
1. 시계열 데이터패턴 추출
: 시계열 파생변수 종류
- 빈도(Frequncy) : 계절성 패턴(Seasonality)이 나타나기 전까지 사람이 정의

- 추세(Trend) : 시계열이 시간에 따라 증가, 감소 또는 일정 수준을 유지하는 경우
- 계절성(Seasonaliy) : 일정한 빈도로 주기적으로 반복되는 패턴
- 주기(Cycle) : 일정하지 않은 빈도로 발생하는 패턴
- 더미변수(Dummy Variables) : 이진수의 형태로 변수를 생성하는 것으로 휴일, 이벤트, 캠페인, 아웃라이어 등을 생성 가능
- 지연값(Lagged values) : 변수의 진연된 값을 독립변수로 반영하는 것으로 ARIMA/VAR/NNAR 등이 활용
- 시간변수 : 시간변수를 미시/거시 적으로 분리하거나 통합하여 생성된 변수(YEAR/M/D/H 등)
: 시계열 구성요소는 각 변수의 시간패턴을 파악하는데 중요
: FE를 통해 생성된 변수의 입력 형태로 모형 선택을 하는데 필요
: 생성된 변수의 패턴이 기존 모델에서 반영하지 않던 패턴이라면 예측 성능을 높임
: 예측 성능 향상 뿐 아니라 결과를 해석하고 해당 속성을 분리하며 가능한 원인 식별에 도움
2. 시계열 데이터 분리
: 비시계열 데이터 준비(시간 차원을 보존하지 않음)
- 훈련 데이터(Train set) : 통상적으로 전체 데이터 셋 중 60% 사용, 과거
- 검증 데이터(Validation set) : 통상적으로 전체 데이터 셋 중 20% 사용, 과거
- 테스트 데이터(Test set) : 통상적으로 전체 데이터 셋 중 20% 사용, 미래
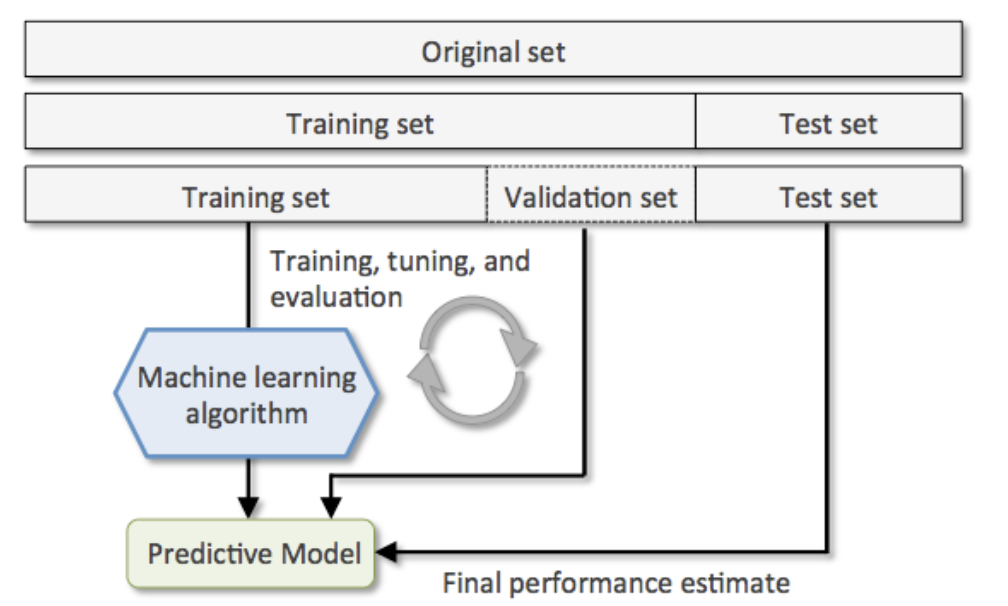
: 비시계열 데이터 나누는 방법
- 홀드아웃(Hold-Out) : 데이터 셋을 고정(일정 비율 2:8, 3,7 등)
- 교차 검증(K-Fold) : 훈련셋을 복원 없이 K개로 분리한 뒤 테스트 셋은 1개, 훈련 셋은 K-1 개
- Levae - One - Out : 테스트 셋 1개, 훈련셋 N-1 개
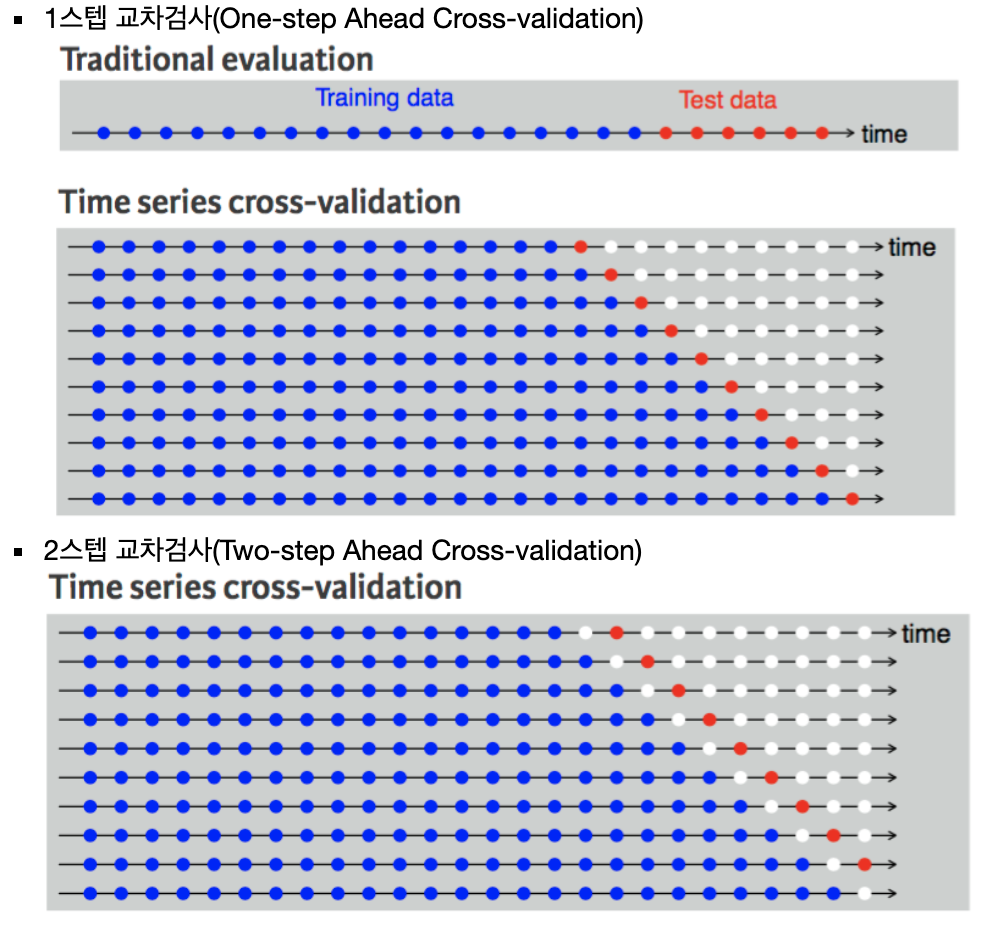
: 시계열 데이터 준비(시간 차원을 보존, 날짜를 정하는게 가장 핵심)
- 훈련 데이터(Train set) : 가장 오래된 데이터
- 검증 데이터(Validation set) : 그 다음 최근 데이터
- 테스트 데이터(Test set) : 가장 최신의 데이터
: 시계열 데이터 나누는 방법(단기와 장기 모델을 나눠서 만들어 사용하는것이 제일 합리적이고 효과적임)
- 1스텝 교차검사(One-step Ahead Cross-validation) : 1번째 시점을 Test Set으로 사용
- 2스텝 교차 검사(Two-step Ahead Cross-validation) : 2번째 시점을 Test Set으로 사용
반응형
'Data Science > 02_Time Series Analysis' 카테고리의 다른 글
| 시계열 데이터 전처리3 (0) | 2020.12.16 |
|---|---|
| 시계열 데이터 전처리2 (0) | 2020.12.15 |
| 잔차 진단 (0) | 2020.12.14 |
| 가설 검정 (0) | 2020.12.02 |
| 시계열 및 통계 용어 (0) | 2020.11.27 |