2020. 12. 15. 18:59ㆍData Science/02_Time Series Analysis
시계열 데이터 전처리시 유의사항
: 시계열 데이터 분석에 앞서 데이터를 정제할 때 숙지해야 하는 점을 정리하고자 함
1. 시간영역(해상도) 선택
: 시계열이 분석효과에 도움이 될 시간영역(해상도)을 분석가의 경험과 지식을 기반으로 선택해야 함
: 일반적으로 예측 정확성이 높은 시간영역을 선택하거나 예측 결과를 다시 학습으로 사용하여 연속적으로 사용함
: 연간 단위 비즈니스 목표 예측을 예시로
- 월별 또는 분기별 데이터를 사용하면 연간 데이터보다 나은 예측이 가능할 것
- 월/분기별 예측치를 연간으로 환산시 오류가 늘어날 것 같지만 실제로븐 반대의 경우가 많음
- 너무 세분화된 시간영역을 사용할 시 오류가 증가될 수 있음
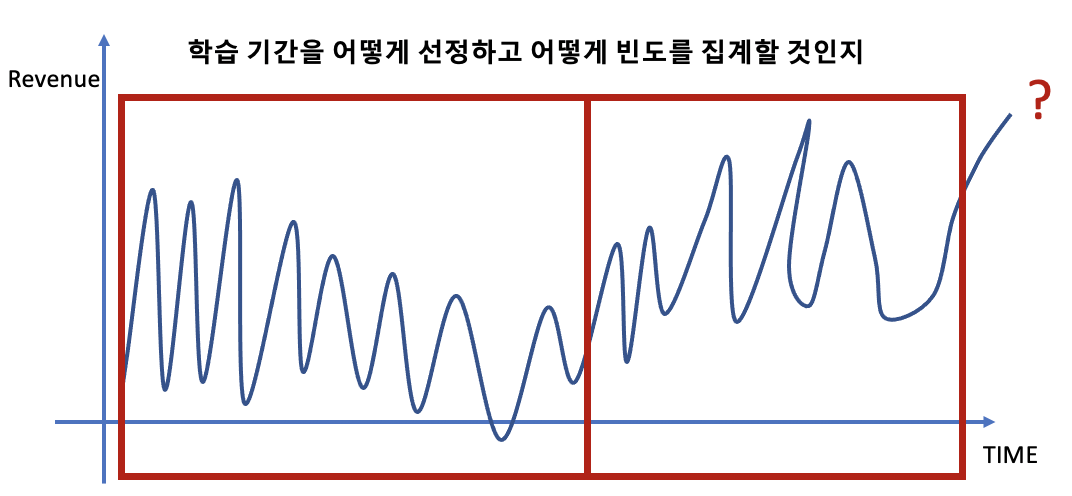
2. 높은 정확도 or 높은 에러
: 시계열 데이터/분석은 높은 정확도를 낳거나 높은 에러를 발생시킴
: 높은 정확도(High Accuracy)는 과거 패턴이 미래에도 그대로 유지가 된다면 예측 정확도가 높아짐
: 높은 에러(High Error)는 패턴이 점차적으로 또는 갑자기 변경되면 예측값은 실제값에서 크게 벗어날 수 있음
- Black Swan : 일어날 것 같지 않은 일이 일어나는 현상
- White Swan : 과거 경험들로 충분히 예상되는 위기지만 대응책이 없고 반복될 현상
- Gray Swan : 과거 경험들로 충분히 예상되지만 발생되면 충격이 지속되는 현상
3. 시계열 데이터 관리
: 수천/수백만/수십억 데이터를 기계학습에 사용할 수 있지만 시계열로 데이터를 정리하면 데이터 감소 발생 가능
: 모든 시간범위가 예측성능에 도움되지 않을 수 있기에 특정기간의 시간영영 분석만 필요할 수도 있음
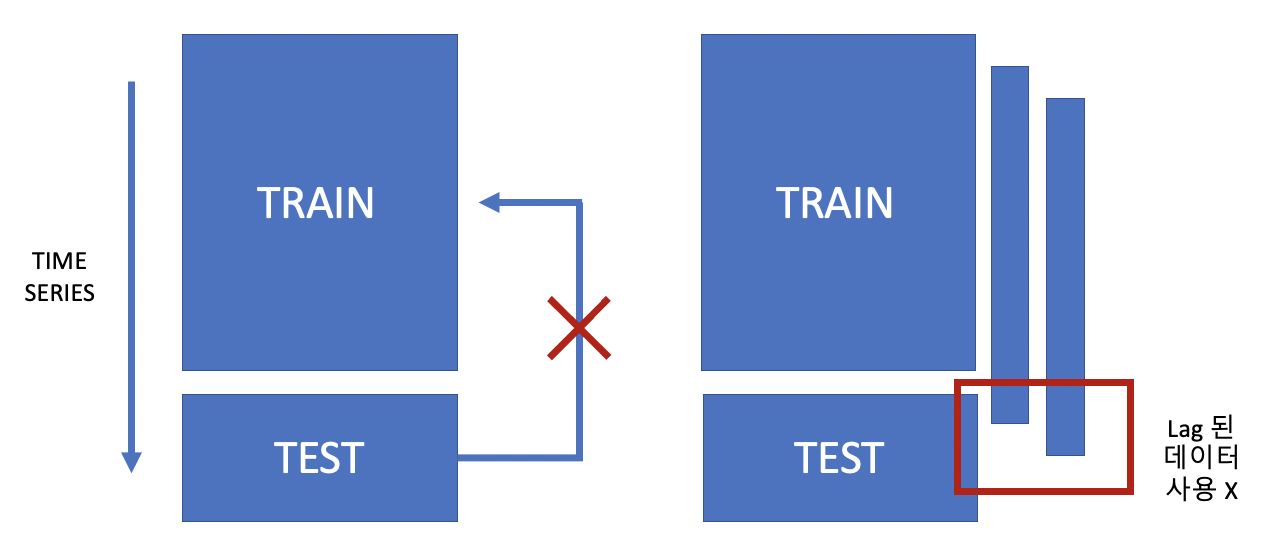
4. 시간현실 반영
: 미래의 시간패턴을 미리 반영하는것은 비현실적이며 이는 과적합(Overfitting)을 유발함
: 이는 기계학습에서 Test Set을 절대 사용하면 안되는 이유이며, 일반화 성능을 하락시키는 주된 원인이 됨
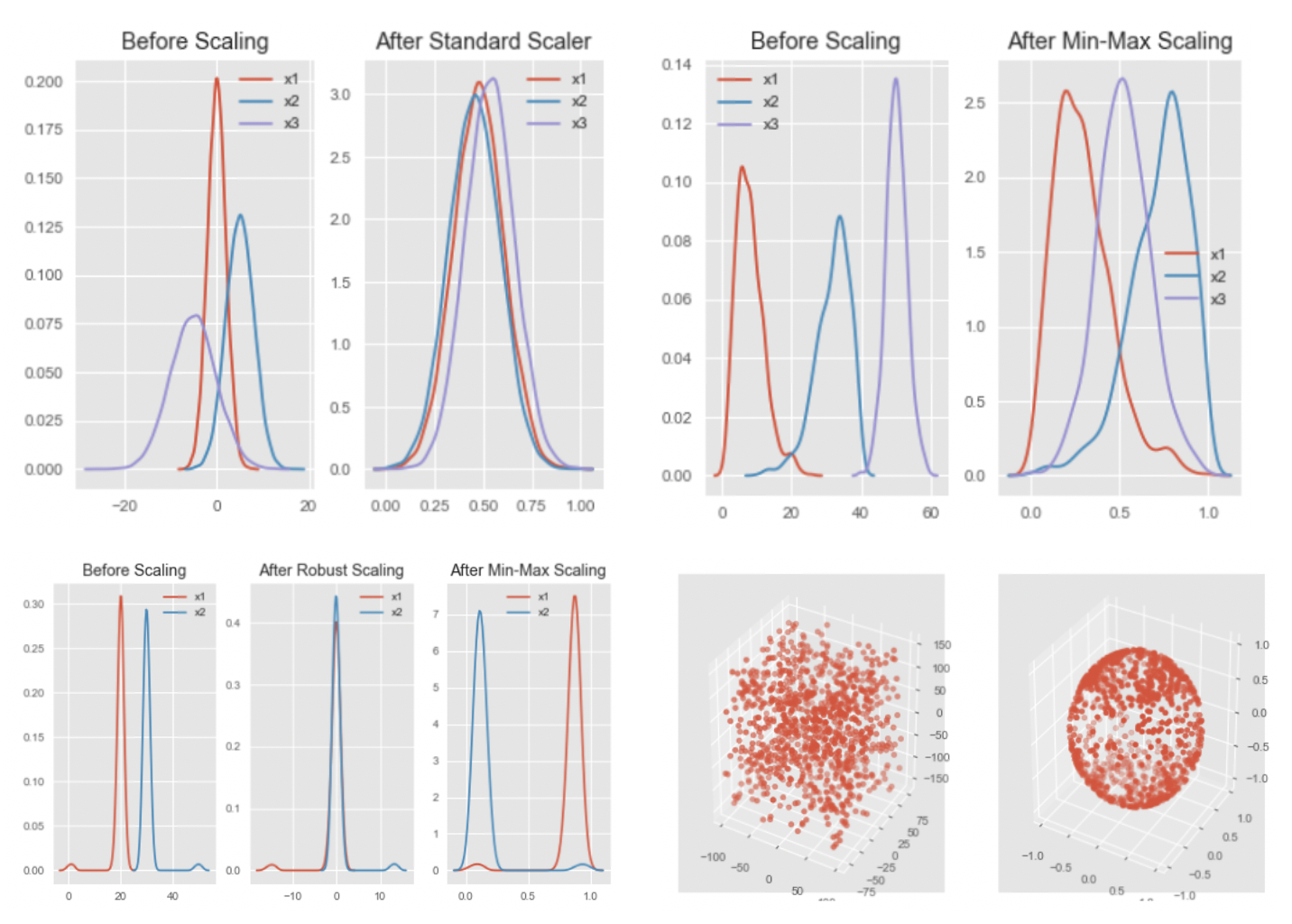
5. 조건수(Cond. No.) 감소
: 분석 결과 안정성을 확보하기 위해서 조건수를 감소시켜야 함
: 조건수를 줄이기 위해 일반적으로 2가지 방법을 사용함
- 스케일링(Scaling) : pc메모리를 고려하여 오버플로우나 언더플로우를 방지하고 독립 변수의 공분산 행렬 조건수를 감소시킴
- Standard Scaler : 평균을 제외하고 표준편차로 나누어 변환(정규 분포를 가정시 사용)
- Min-Max Scaler : 가장 많이 활요되며 최소~최대 값이 0~1 또는 -1~1 사이로 변환(정규 분포 가정을 안함)
- Robust Scaler : 최소-최대 스케일러와 유사하지만 최소/최대 대신 IQR중 1분위수와 3분위수를 사용하여 변환
- Normakuzer : 각 변수들 전체 n개 모든 변수들의 크기들로 나누어서 변환, 모든 변수들의 값은 원점으로 부터 반지름 1 이내
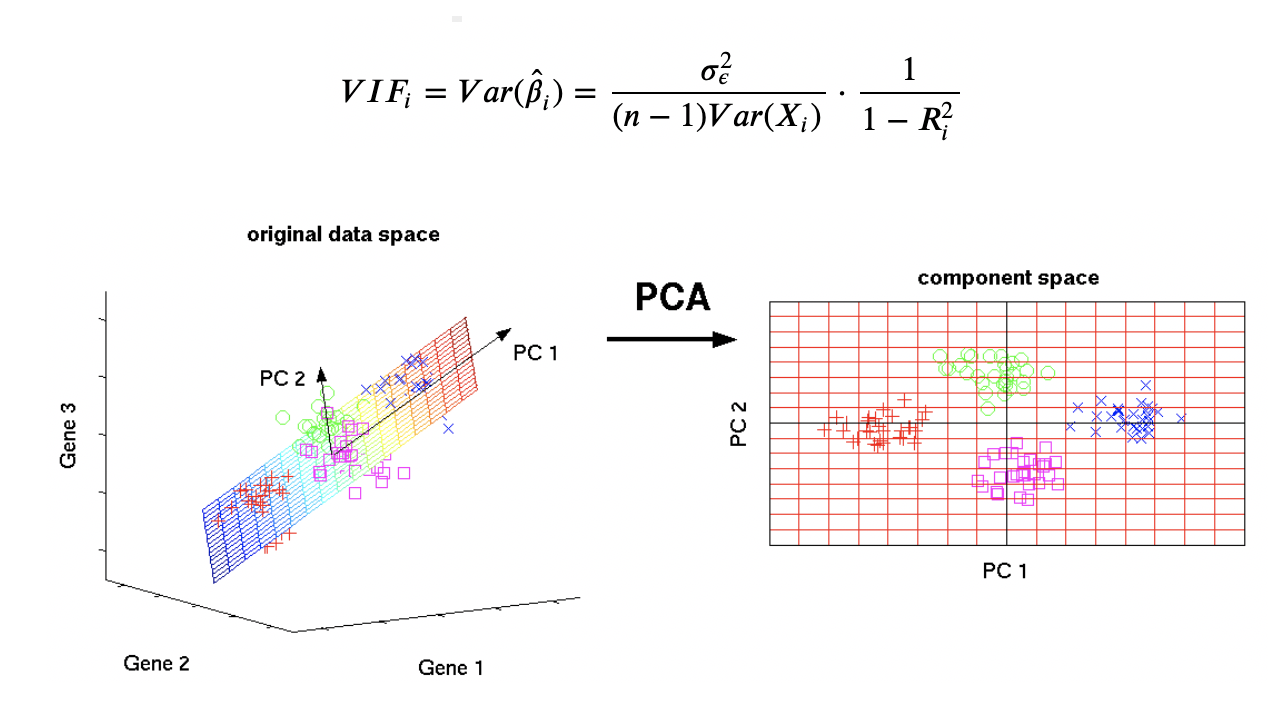
- 다중공선성(Multicollinearity) 제거 : 독립변수의 일부가 다른 독립변수들의 조합으로 표현될 수 있는 경우 등 발생
- Variance Inflation Factor(VIF) 변수 선택 : 의존성이 낮은 변수 선택 혹은 높은 독립변수를 제거
- Principal Component Analysis(PCA) 변수 선택 : 서로 독립인 차원의 독립변수 행렬로 변환시키는 알고리즘
'Data Science > 02_Time Series Analysis' 카테고리의 다른 글
| 정규화(Regularization)/배깅(Bagging)/부스팅(Boosting) (0) | 2020.12.17 |
|---|---|
| 시계열 데이터 전처리3 (0) | 2020.12.16 |
| 잔차 진단 (0) | 2020.12.14 |
| 시계열 데이터 전처리1 (0) | 2020.12.10 |
| 가설 검정 (0) | 2020.12.02 |